Nous arrivons donc à la dernière phase du cycle du renseignement, celle de la diffusion de l’information, et les questions à traiter ici sont communes à toute action de communication :
- Qui en sont les destinataires ?
- Quels sont leurs besoins en informations? (question qui aura normalement trouvé sa réponse durant la phase d’orientation générale).
- Comment « consomment-ils » l’information? Textuelle? Graphique? Audio?…
- Quelles sont leurs habitudes de lecture? Papier, sur PC, tablettes, smartphones,…
- etc
Les modèles de langage ne sont pas directement utiles pour répondre à ces questions, tout du moins pas avant qu’ils ne soient intégrés à des outils d’aide à l’analyse de données telles que les statistiques de consultation d’une newsletter, d’un rapport, ou de tout autre livrable. Et cela ne saurait tarder. Voici par exemple un tableau de données sur la consommation d’énergie en France entre 1990 et 2019 que j’ai simplement copié-collé dans ChatGPT avec le prompt suivant :
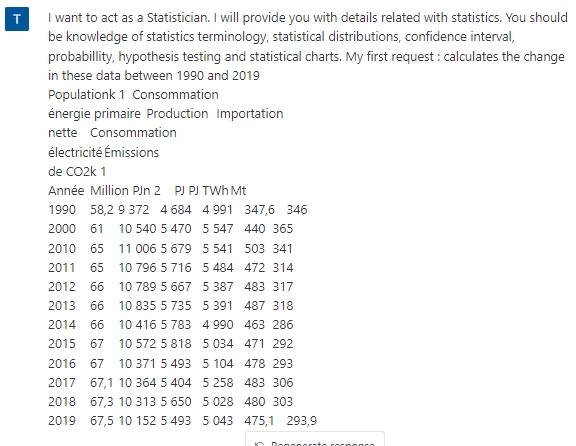
Voici sa réponse :
Même s’il y avait quelques erreurs, ce qui n’est pas le cas ici, ce ne serait qu’une question de temps avant qu’il n’y en n’ait plus (le « learning » dans « machine learning »…) et que l’outil vous aident à analyser des statistiques quelles qu’elles soient.
Cibler les informations issues de la veille stratégique en fonction des profils de destinataires
C’est évidemment l’un des enjeux majeurs et l’une des possibilités les plus excitantes de ces outils. En effet, on peut facilement imaginer des dispositifs dans lesquels le modèle apprendra des habitudes de lecture et de consultation des destinataires. On commencera par le « nourrir » de données individuelles internes à l’organisation (productions documentaires de chacun, emails, transcriptions de prises de parole lors de réunions,…). Le profil sera ensuite affiné à chaque interaction d’un employé avec l’information que lui diffusera le dispositif, à l’instar du modèle de captation de données personnelles des réseaux sociaux ou, de manière plus évidente encore, des services (type Amazon, Spotify, Google actus, Facebook,…) utilisant des algorithmes de recommandation. Et c’est là où se pose (au moins) deux premières questions qui fâchent :
- Quels sont les droits de l’employé sur ses données personnelles dans le cadre professionnel ? Doit-il accepter que son profil professionnel soit exploité de cette manière ?
- Comment ne pas recréer des bulles de filtres qui iraient, par principe, à l’encontre de l’objectif d’ouverture et d’objectivité de tout dispositif de veille.
Si la première question est inquiétante et mettra du temps à trouver des réponses, la seconde pourrait l’être un peu moins à partir du moment où le modèle sera configuré pour « mixer » les besoins du veilleur ou de l’analyste avec, par exemple, une part des contenus qui intéressent ses collègues exerçant la même fonction que lui dans l’organisation et, pourquoi pas, avec une troisième part de contenus à l’opposé, ou à la limite de ce avec quoi il interagit habituellement. Un cocktail statistique à bien doser en somme et où les dosages devront être laissés à l’appréciation de l’utilisateur.
Structurer et présenter les informations à diffuser selon les profils de destinataires
Dans la même logique, les modèles de langage sont déjà en mesure d’adapter leur discours en fonction des « cibles » (au sens où la communication utilise ce terme) qu’ils adressent. Ainsi, ils sont capables de présenter la même analyse de plusieurs manières, s’adaptant en cela aux modes de consommation de l’information des destinataires de l’information issue de la veille. Au fil du temps, ils connaîtront de mieux en mieux ces habitudes et seront donc de plus en plus ajustés. Voici par exemple le même texte de départ synthétisé par ChatGPT pour des décideurs, puis pour des enfants.
Synthèse pour décideurs :

Synthèse pour des enfants :

On constate qu’il est parfaitement capable de s’adapter à différents registres de langage.
Synthétiser de grandes quantités d’information
Comme nous l’avions déjà constaté, les modèles de langage sont très à l’aise dans le résumé de texte. C’est notamment la force de l’extension WebChatGPT qui collecte des résultats de Google afin que ChatGPT les synthétise. On peut aussi utiliser des extensions permettant de résumer des articles en ligne. Plusieurs existent déjà, comme par exemple Summarize. La suite logique de tout cela est bien sûr de leur donner à synthétiser des corpus choisis. Par exemple les derniers articles de recherche sur une thématique, les 50 derniers articles de presse traitant du retour du nucléaire en France ou encore le bilan annuel d’un concurrent. De fait, ce sont des possibilités qui existent déjà. Ainsi, depuis deux ans déjà, on peut utiliser Power Automate de Microsoft pour exploiter GPT3 dans son environnement de travail. Bien sûr ChatGPT est lui aussi déjà intégré. D’autres exemples existent comme TwitterGPT (pas facilement testable) qui permet de récupérer les tweets d’une timeline et de les résumer. Plus simple à tester, l’excellent projet de veille automatisée « Ouvrir la politique » de Mathieu Andro. Il intègre le plugin WordPress Cyberseo Pro, qui va résumer automatiquement les articles récupérés. Pour l’instant Mathieu ne l’a déployé que pour quelques sources mais cela permet de comprendre son usage potentiel sur d’autres types de contenus.
Les questions qui fâchent…
Bien entendu, même si tout cela apporte des perspectives fascinantes, il est évident que ce n’est pas si simple… Et comme indiqué précédemment, nous avons attendu la fin de cette série pour évoquer les questions qui fâchent.
Tout d’abord parlons de la fiabilité des réponses. Il y a déjà eu pléthore d’articles pour pointer du doigt le problème de la véracité ou de la justesse des réponses de ChatGPT. Oui ChatGPT raconte souvent n’importe quoi, il invente des références bibliographiques et c’est parfaitement normal lorsqu’on comprend un minimum comment il fonctionne (cf. par exemple cette excellente vidéo de Monsieur Phi). C’est qu’il n’est pas fait pour dire le vrai, donner des éléments factuels ou cogiter mais simplement pour rédiger du texte crédible. Il glose, il jase et paraphrase car il est fait pour ça et ne fonctionne finalement pas différemment de la saisie prédictive de votre smartphone. Enfin si, un peu quand même, comme on a pu le voir tout au long de cette série d’article, mais il faut savoir le prendre… Concrètement, c’est un assistant qui ne réfléchit pas, un exécutant dont les réponses resteront du niveau des questions que vous lui posez. Si vous demandez à un ami de vous trouver des références sur un sujet qu’il ne maîtrise pas, vous n’obtiendrez rien de bien intéressant. Si en revanche vous l’aiguillez en lui donnant quelques éléments de départ : noms d’auteurs, sources pertinentes, etc, il vous rapportera des éléments plus intéressants. De fait, plus vous connaissez votre sujet et plus vous êtes en mesure de poser des questions pertinentes, mais surtout d’évaluer la qualité des réponses de ChatGPT et de le pousser dans ses retranchements. C’est donc dans l’orientation de l’outil que tout se joue et c’est là finalement où les mauvais élèves vont se trouver face à une petite difficulté… Ou comment faire faire son devoir de philo par son petite frère qui, certes, ne fait pas de fautes mais en connait encore moins que vous sur le sujet…
C’est également ici que se joue la « compétition » avec Google, compétition qui de fait n’existe pas pour ce qui est du factuel. Google donne des sources, il ne « dit pas le vrai » ou supposé tel. C’est toujours à vous de faire le travail critique. ChatGPT et consorts sont de « beaux phraseurs » que vous pourriez être tentés de croire sur parole mais il ne faut surtout pas s’y fier pour ce qui est des faits, qu’ils sont parfaitement capable d’inventer à la volée pour avoir quelque chose à répondre. Autre grosse différence avec Google, ils ne donnent pas leurs sources, ce qui devrait bien sûr inquiéter tout professionnel de l’information et, idéalement, tout citoyen.
Pour autant, on ne doit pas les réduire à cet usage dysfonctionnel car c’est ailleurs qu’ils nous seront utiles. Comme nous l’avons constaté, ils pourront être mis à contribution pour :
- l’aide à la créativité,
- l’aide à la réflexion sur un sujet, notamment en phase de démarrage,
- l’aide à la rédaction (structuration d’un plan par exemple),
- la réécriture de passages peu clairs,
- le résumé de textes,
- la traduction automatique,
- le formatage de contenu,
- l’aide à l’analyse de sets de données (statistiques par exemple)
- etc
Un bon artisan (et ne doutons pas que les veilleurs sont des artisans) sait à quel moment et comment utiliser tel vieux ciseau à bois plutôt que tel autre flambant neuf, car il n’ont pas tout à fait les mêmes qualités, pas encore du moins. Et les modèles de langage ne sont que des outils de plus dans notre caisse. Plus les mois (semaines?) passeront et plus il y en aura de différents, adaptés à certaines tâches ou à certains corpus plutôt qu’à d’autres. Tout comme l’on choisit entre Google et Qwant pour faire une recherche (🤣🤣🤣), l’on choisira un modèle de langage plutôt qu’un autre pour traiter tel sujet.
Autre point problématique évident, celui des résumés et synthèses qu’il propose. Quoique impressionnantes, on ne peut évidemment lui faire totalement confiance à ce sujet. La question étant de savoir ce qu’il a sélectionné d’un article ou d’un corpus pour générer son résumé, ou plutôt, ce qu’il n’a pas sélectionné. Bien entendu de nombreuses améliorations arriveront rapidement pour pallier à cette faiblesse : ajout d’un contexte, de mots-clés ou d’entités nommées spécifiques dont il devra tenir compte dans son traitement, etc. Mais comment faire pour que le doute ne subsiste pas…
Par ailleurs, plus globalement, il y aura au moins trois autres « gros » sujets sensibles dans les mois à venir :
- celui des droits d’auteurs
- celui des biais des modèles de langage (comme l’explique très bien la vidéo de Monsieur Phi déjà citée)
- celui de la sécurité des éléments que l’on y dépose et qui a déjà alarmé la direction d’Amazon
- celui de la création ad libitum de faux contenus qui inonderont le web et les réseaux sociaux dans des objectifs d’influence, marketing ou stratégique.
Si le premier ne devrait pas trop impacter les veilleurs et analystes dans les usages recommandés des modèles qu’ils auront, il en va différemment du second qui pourrait tout simplement les couper d’une partie de la réalité en ne laissant entendre qu’un seul son de cloche. L’exact inverse donc de la manière de penser d’un veilleur ou d’un analyste, qui a vocation à embrasser le réel, dans son entièreté et sa complexité, pour alimenter sa propre vision du monde. Quant au troisième, je pense avoir suffisamment documenté son impact dans nos métiers dans cet article de recherche récent.
Comme vous l’aurez constaté à la lecture de cette série d’articles, les modèles de langage comme ChatGPT vont avoir un fort impact sur nos métiers et plus globalement sur toutes les fonctions où l’information écrite, est centrale. Cela fait beaucoup de monde et pourrait bien arriver très rapidement tant les outils sont simples à prendre en main.
Ce qui est sûr c’est que ce que l’avenir nous réserve est plutôt enthousiasmant, à condition bien sûr de faire en sorte de ne pas le subir…
Rappel : pour intégrer ChatGPT et GPT3 à votre travail quotidien, vous pouvez utiliser les extensions et services que je compile dans cette base de données Airtable.


1 commentaire